🔍 Dobrodošli v novi dobi spletnega iskanja
Še pred meseci smo se borili in optimizirali vsebino za prvo mesto med desetimi modrimi povezavami.
Danes pa več kot 60 % iskanj v Googlu – še vedno največjem iskalniku na svetu – konča brez enega samega klika.
Uporabniki vprašajo, dobijo odgovor in zaprejo zavihek.
Brez obiska spletne strani, brez brskanja po rezultatih, brez klasične poti skozi SEO lijak.
Trend se ne upočasnjuje – prav nasprotno.
Marca 2025 je Google s posodobitvijo razširil AI Overviews tudi na področja, kot so potovanja, prehrana in zabava.
Organski promet je takoj upadel, številke v analitikah pa povedo svoje: uporabnik dobi odgovor že na vrhu – in pogosto tam tudi ostane.
💡 In tukaj se pojavi nova priložnost.
Iskalniki, ki jih poganjajo veliki jezikovni modeli (LLM-ji), kot so ChatGPT, Perplexity ali Gemini, potrebujejo vire, iz katerih gradijo svoje odgovore.
In če znaš pisati tako, da izberejo tvoje besedilo, postaneš viden tudi brez klika.
Dobesedno postaneš del odgovora.
Hkrati Perplexity vsak dan obdela okoli trideset milijonov vprašanj – to je približno sedemsto osemdeset milijonov na mesec – in v vsak odgovor vključi le peščico virov.
Če želiš ostati viden, moraš pisati tako, da te iskalniki z velikimi jezikovnimi modeli (LLM‑ji) najdejo, razvrstijo in citirajo.
Ta praksa se imenuje LLM SEO oziroma Generative Engine Optimization (GEO).
🤖 Kaj je LLMSEO – in zakaj ga ne smeš spregledati
LLMSEO (ali GEO – Generative Engine Optimization) je optimizacija za generativne iskalnike.
Ne cilja na uvrstitev na seznamu Googlovega SERP-a, ampak na omembo znotraj generiranega odgovora.
To pomeni, da se tvoje besedilo znajde neposredno v odgovoru, ki ga vidi uporabnik, tudi če ne klikne nobene povezave.
Veliki jezikovni modeli razdelijo tvojo stran na manjše enote – običajno med 60 in 120 besed – jih ovrednotijo po relevantnosti, svežini in jasnosti ter najboljše uporabijo kot gradbeni material za svoje odgovore.
Če je tvoj odstavek dovolj dober, ga povzamejo skoraj dobesedno. In to pomeni vidnost, zaupanje in prepoznavnost brez klasičnega klika.
Zakaj ravno sedaj?
Zato ker se splet spreminja.
Oziroma drugače.
Ker se spremina način iskanja.
In ker podatki ne lažejo.
Perplexity dnevno obdela več kot 30 milijonov vprašanj in v vsak odgovor vključi le tri do deset virov. Uvrstitev mednje postaja nova valuta spletne vidnosti.
Analize kažejo, da odločilno vlogo pri tem igrajo svežina vsebine, visoka gostota dejstev in jasna struktura z uporabo sheme FAQ.
Hkrati se pojavljajo novi pajki, kot je r.jina.ai, ki obiskujejo tvojo stran ne zato, da bi poslali uporabnika do tebe, temveč da tvojo vsebino “preberejo”, pretvorijo v vektorje in jih pripravijo za uporabo v LLM bazi.
Tvoja vsebina torej že zdaj sodeluje v igri odgovorov – vprašanje je le, ali bo izbrana.
Kako deluje LLMSEO znotraj iskalnika?
Če želiš vedeti, kako priti v odgovor generativnega iskalnika, moraš najprej razumeti, kako sploh “bere” tvojo stran.
Ključ ni v estetiki ali dizajnu – LLM ne zanima tvoja tipografija ali barvna shema. Zanima ga surova vsebina.
In ta se analizira drugače kot v klasičnem SEO-ju.
1. Pajek pobere čisti HTML
Ko generativni iskalnik obišče tvojo stran, najprej odstrani vse nepotrebne skripte – od oglasov do analitike – in ostane le čist HTML. Vse, kar je napisano v tekstu, preživi. Vse ostalo gre stran.
Če si bil doslej pozoren le na to, kaj vidi uporabnik, je zdaj čas, da se vprašaš: kaj vidi stroj?
2. Besedilo se razreže na koščke
Iskalnik tvoje besedilo razbije na majhne enote – običajno dolge od 64 do 128 tokenov, kar je približno 60–120 besed. Zakaj ta razpon? Raziskave kažejo, da je to optimalna dolžina za ravnovesje med kontekstom in natančnostjo.
Vsak košček – odstavek, trditev, odgovor – postane samostojna enota, ki tekmuje za svojo priložnost, da se znajde v odgovoru.
3. Vsak vsebinski odsek = vektorska vsebina
Tu nastopi matematika.
Vsak tekstovni kos se s pomočjo vdelovalnika (ang. embedder) pretvori v vektor – številčno predstavitev pomena.
Iskalnik nato primerja te vektorje s poizvedbo uporabnika.
Bližje kot je tvoj vektor vprašanju, večja je verjetnost, da bo izbran.
To je semantično ujemanje – kjer šteje pomen, ne zgolj ključne besede.
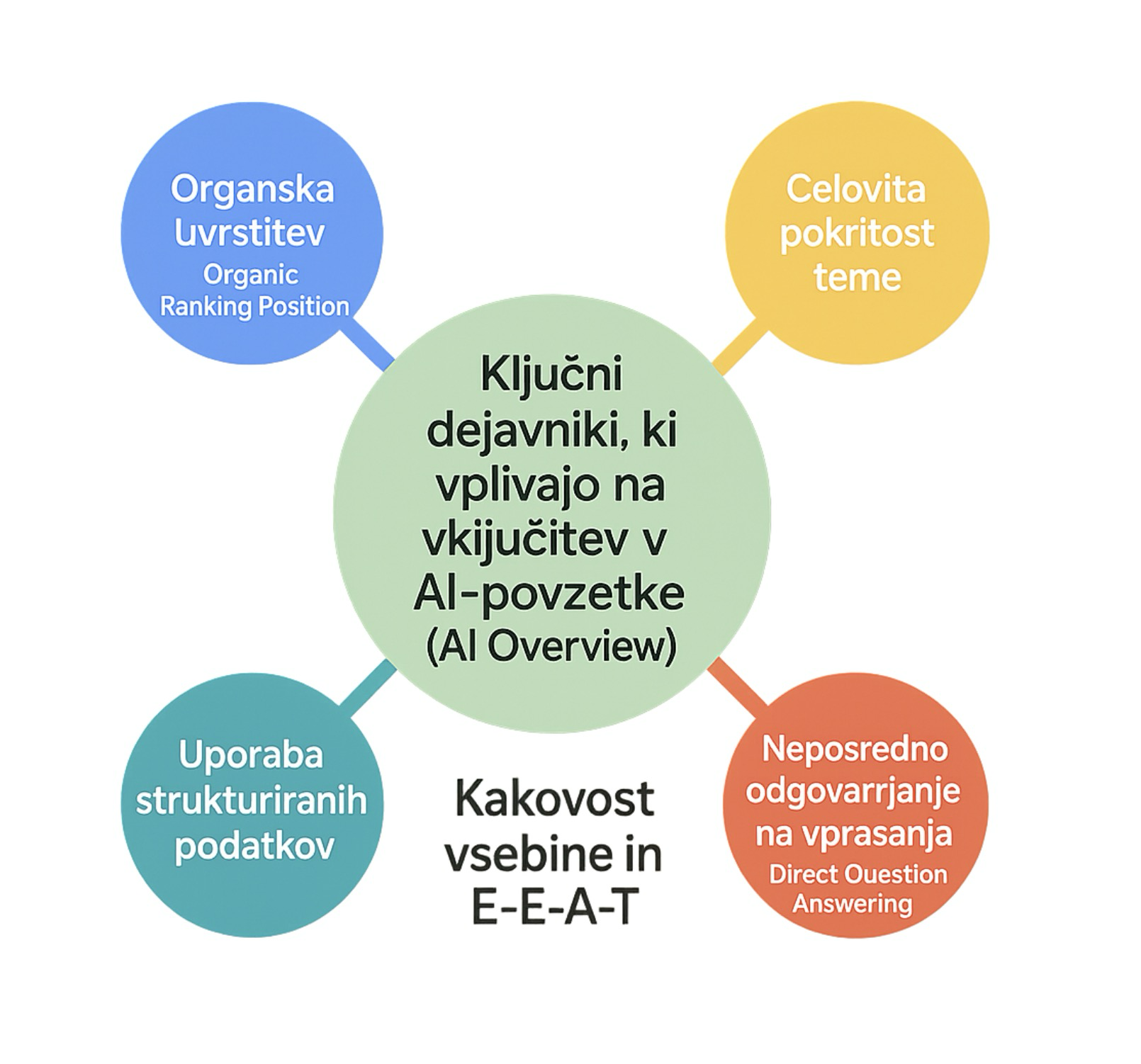
4. Vključijo se signali kakovosti
Podobno kot Google uporablja sistem E‑E‑A‑T (izkušnje, strokovnost, avtoriteta, zanesljivost), tudi LLM iskalniki ocenjujejo kakovost.
Gledajo na:
- svežino vsebine (kdaj je bila nazadnje posodobljena),
- verodostojnost (ali je vsebina napisana jasno in nedvoumno),
- avtorja in reference (je vsebina podpisana, so v njej citirane zanesljive študije),
- strukturo in jezikovno preprostost (kratki stavki, jasni naslovi, logični prelomi).
Inženirji pri Perplexityju so celo javno povedali, da ob enaki relevantnosti dajo prednost svežim vsebinam.
5. Sledi sinteza odgovora
Na koncu vstopi v igro generativni model, kot je GPT‑4o ali Gemini 2.5.
Ta vzame najboljše ocenjene odstavke in jih poveže v enoten, tekoč odgovor. Pri tem pogosto ohrani prvotne stavke skoraj nespremenjene – če so bili dovolj dobro napisani.
To pomeni, da lahko tvoj odstavek – če je dovolj jasen, informativen in dobro strukturiran – preživi pot od tvoje strani do vrha odgovora v skoraj nespremenjeni obliki.
Kaj vse to pomeni za tvojo vsebino?
Pravzaprav je vse skupaj dokaj preprosto: piši tako, kot bi želel, da te LLM-ji razumejo in uporabijo. Iz zgornjega poteka lahko izluščimo konkretne napotke.
Kako torejprilagoditi strategijo ustvarjanja vsebine za LLMSEO:
Osredotoči se na kratke, jedrnate odstavke
Vsak odstavek naj nosi eno glavno misel in naj bo dolg recimo 50–120 besed. Predolg, razvlečen odstavek tvega, da bo razbit in izgubil kontekst, ali pa da bo vseboval preveč balasta. Rajši razdeli kompleksno misel v več manjših odstavkov.
Uporabi jasne naslove in format FAQ
Struktura je ključna.
Redno uporabljaj podnaslove, vprašanja in odgovore kot v FAQ formatih. Takšna struktura ne pomaga le bralcu, ampak tudi LLM-ju: jasno označena vprašanja in odgovori so idealni kandidati, da jih AI vzame neposredno za odgovor na podobno uporabniško vprašanje.
Povečaj “gostoto” dejstev in uporabnih informacij
AI orodja obožujejo konkretna dejstva, številke, definicije.
Če v vsak odstavek vključiš kakšno statistiko, definicijo pojma ali pomembno trditev, bo ta odlomek bolj izstopal.
Skrbi za svežino vsebine.
Redno posodabljaj svoje članke, tudi če le z majhnimi izboljšavami ali najnovejšimi podatki. Svežina je postala zelo pomemben signal. Perplexity bo ob dveh enako relevantnih odlomkih skoraj gotovo izbral tistega iz novejšega članka. Tudi Google vsaj od posodobitve Helpful Content naprej daje večjo težo sveže posodobljenim stranem, kar se odraža tudi v AI povzetkih. Torej, če imaš neko temo že pokrito, jo čez nekaj mesecev osveži – dodaj nov odstavek, posodobi letnico, vstavi novejši primer.
Včasih že ta kozmetična sprememba lahko pomeni, da bo tvoj odsek prehitel drugega v tekmi za vidnost.
Ohrani jezik preprost in jasen
Izogibaj se dolgim, zavitim stavkom in pretirani rabi žargona (razen, če pišeš za ozek krog strokovnjakov). Kratki stavki in enostavne besede pomagajo modelu, da brez dvoumnosti razume tvojo vsebino. Spomni se: LLM razume jezik statistično – če je manj možnosti za napačno interpretacijo, tem bolje.
Izkaži avtoriteto in zaupanje
Podpiši svoje vsebine z avtorjem, dodaj kratko bio z omenjenimi izkušnjami ali strokovnimi nazivi. Vsebina naj ima jasno naveden vir podatkov, kjer je to relevantno (npr. povezave na študije, uradne statistike). Vse to so signali, da je tvoja vsebina vredna zaupanja.
Grajenje prisotnosti je pomembno tudi izven lastne strani
LLM-ji črpajo odgovore iz celotnega spleta, ne le iz tvoje strani. To pomeni, da je koristno imeti svojo blagovno znamko ali strokovne izjave omenjene na uglednih mestih. Če na primer želiš, da ChatGPT “pozna” tvoje podjetje, je dobro, da se le-to omenja v novicah, Wikipediji, strokovnih forumih itd., saj bodo ti viri morda del učnih podatkov.
Za slovenski spletni prostor vse navedeno velja enako, le da moramo upoštevati še jezik.
Trenutno so veliki modeli zelo sposobni razumeti in generirati slovenščino, a večina vsebin, ki jih berejo, je globalno še vedno v angleščini.
To pomeni, da slovenske strani tekmujejo ne le med sabo, ampak tudi z angleškimi (če uporabnik sprašuje v angleščini, bo AI povlekel tuje vire; če v slovenščini, bo iskal po domačih, a morda tudi prevedel tuj vir).
Kljub temu Google za lokalna vprašanja (npr. “kateri so najboljši slovenski filmi?”) seveda raje vzame lokalne vire.
Zato pripravi svojo vsebino tudi za slovenska vprašanja – uporabi slovenski jezik, lokalne primere, hkrati pa lahko kdaj napišeš kakšno stvar dvojezično ali objaviš angleški povzetek, da te pobere še kak tuj AI.
Vsekakor pa velja: slovenske spletne strani ne smejo zaostajati – globalni trendi se hitro preslikajo.
Ko bo Google v celoti uvedel AI-povzetke tudi za slovenske poizvedbe, želimo biti pripravljeni in med izbranimi viri. Že danes pa marsikdo v Sloveniji uporablja direktno ChatGPT ali Perplexity za iskanje; poskrbimo, da bodo ti uporabljali naše spletne znanje, ne le tuje.
LLMSEO v praksi
Teoretično vse lepo in prav – a kako je videti, ko ti uspe?
Poglejmo nekaj primerov in scenarijev, ki ilustrirajo, kako lahko dobra LLMSEO strategija prinese dejansko vidnost:
Citat v Google AI povzetkih
Kmalu po lansiranju AIO (AI Overview) se je na Googlu pojavil AI-povzetek na temo nakupa rabljenega vozila, ki je kot enega od virov navedel članek podjetja MoneySavingExpert.
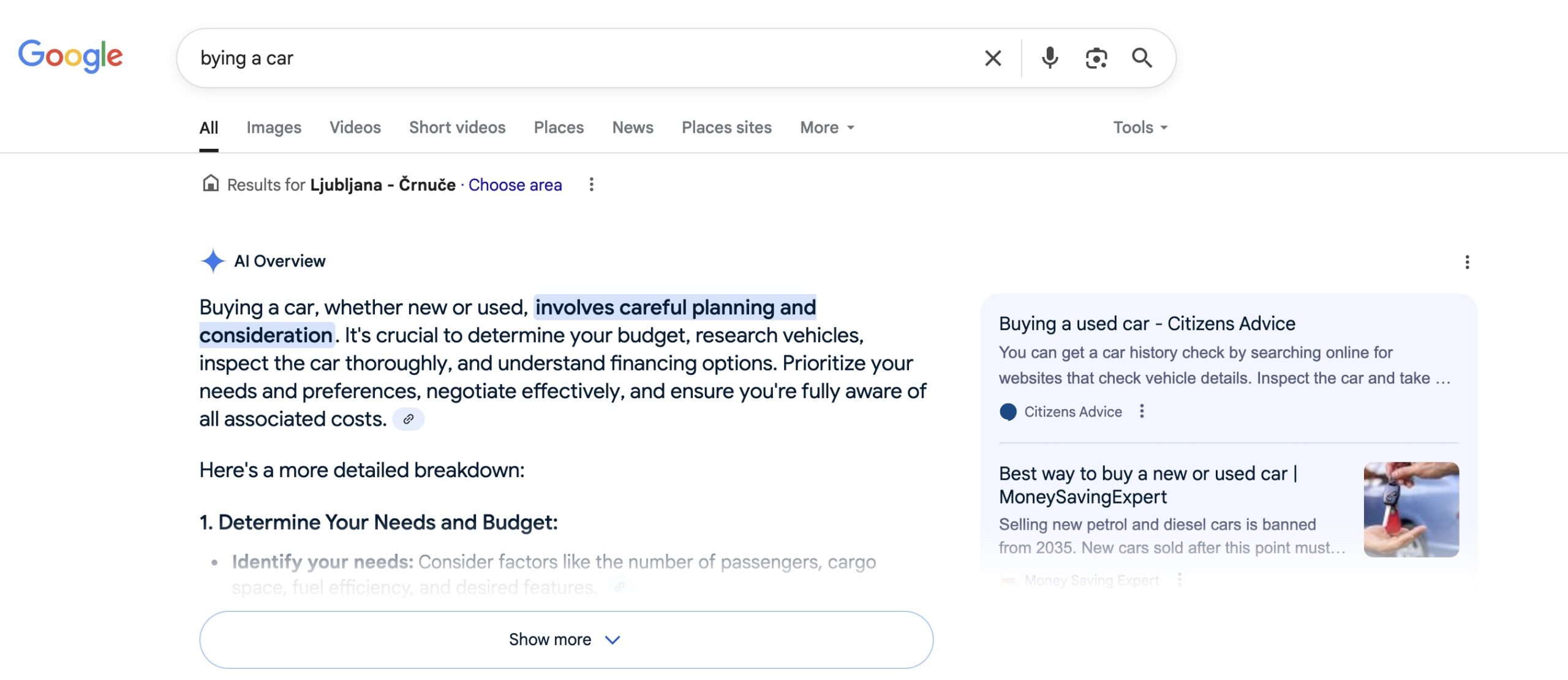
To pomeni, da je Google njihov odlomek ocenil kot tako relevanten in kakovosten, da ga je vključil v svoj generirani odgovor na vrhu SERP.
Za MoneySavingExpert je to izjemna vidnost – njihove besede so dobesedno postale del Googlovega odgovora, uporabniki pa so jih videli, četudi (morda) niso kliknili na stran.
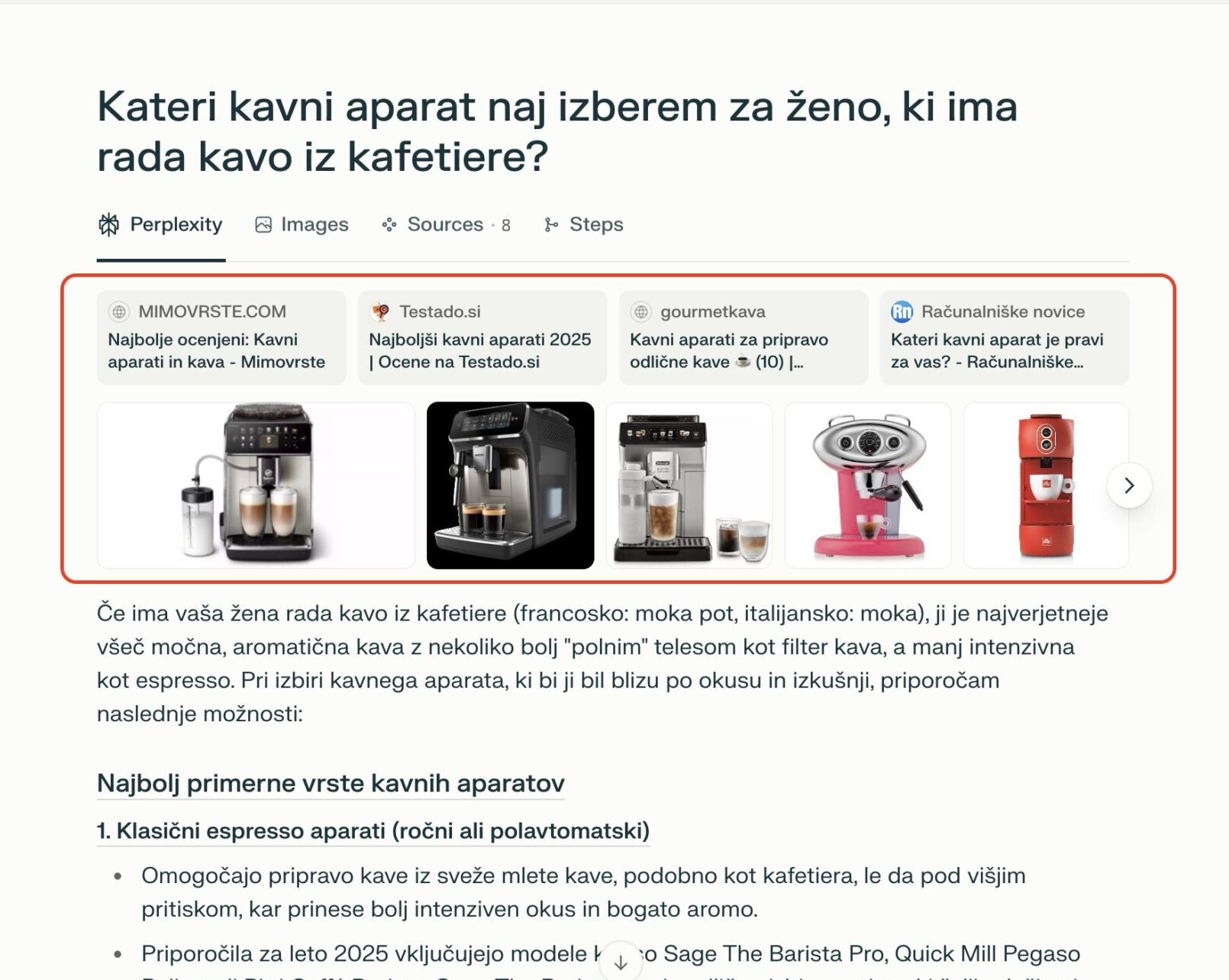
Pojavitev v Perplexity odgovorih
Perplexity pri vsakem odgovoru navede 3–5 virov, ki jih je uporabil.
Dober primer so recimo nekatere spletne trgovine, ki imajo lepo urejene izdelke, opise in dodatne life-style vsebine. Na primer Mimovrste ali Testado oz Gurmetkava.
Lokalen primer – turistične vsebine
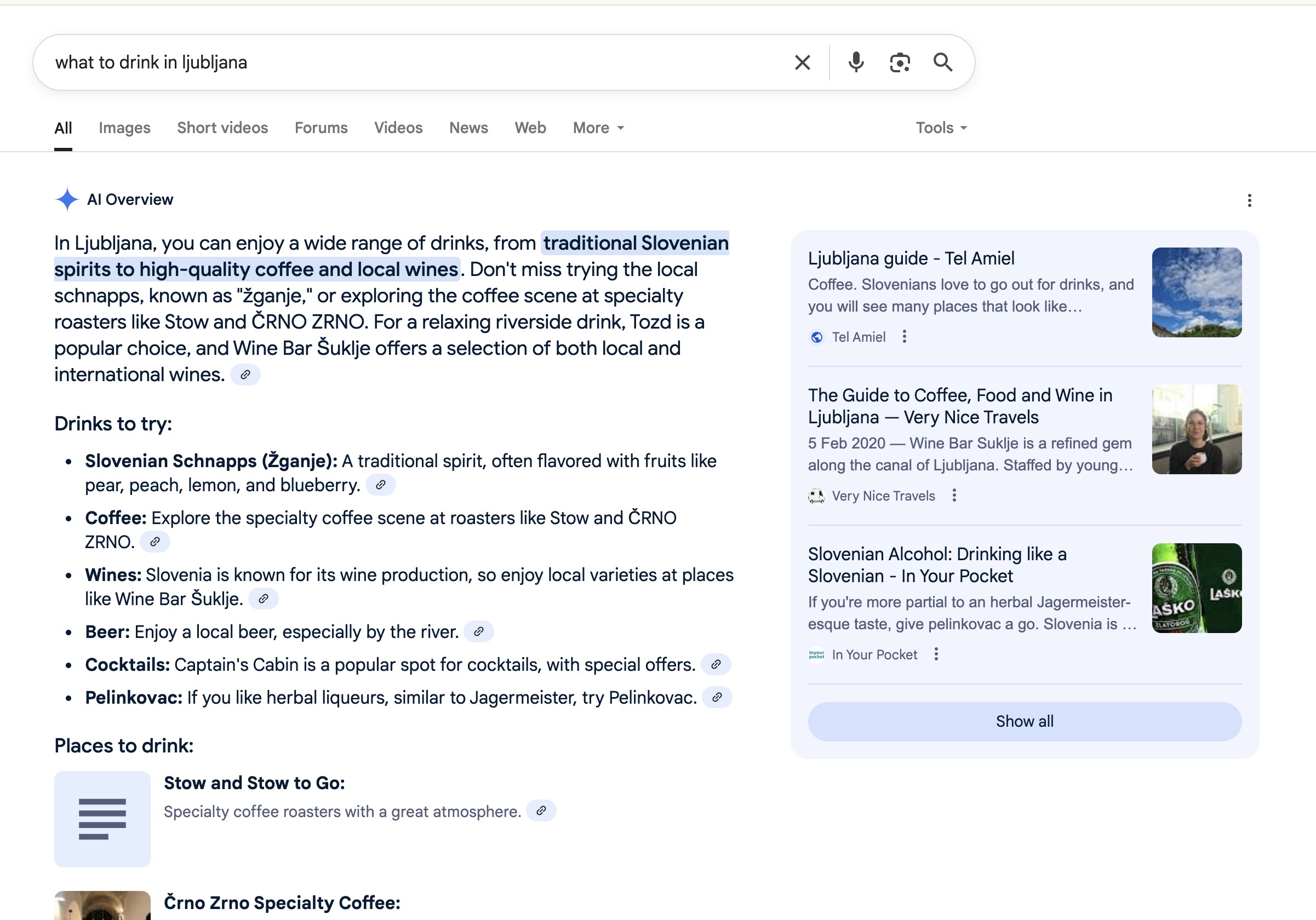
Vzemimo slovenski kontekst: uporabnik vpraša novega Google AI asistenta (ali Bing Chat) nekaj v slogu: “Kam na pijačo oz kaj popiti v Ljubljani”. Zelo možno je, da bo odgovor sestavljen iz povzetkov člankov na turističnih portalih, blogih popotnikov in morda Wikipedije.
Strokovni članki in raziskave
Še en tip vsebine, ki se prebija v AI odgovore, so strokovni članki z veliko podatki. Recimo, znanstveni članek ali poglobljen blog objavi ugotovitve neke raziskave.
Ko kdo vpraša AI npr. “Kakšen je vpliv spanja na produktivnost?”, bo ChatGPT/Perplexity verjetno povzel kakšno študijo.
Če si ti na svojem blogu objavil “Naša anketa: 78 % Slovencev premalo spi, posledice …” in te številke povzeli mediji, lahko tvoje številke končajo v AI odgovorih.
Perplexity daje prednost citiranju podatkov – če jih dobi iz tvoje strani (in oceni, da so verodostojni), boš citiran.
To seveda od tebe terja ustvarjanje res kakovostnih vsebin (npr. lastni mini raziskavi ali analizi), a nagrada je, da postaneš referenca, ki jo navajajo tudi roboti.
Za konec
LLMSEO morda zveni zahtevno, a v bistvu gre za nadgradnjo dobrih praks vsebinskega marketinga in SEO-ja na novo okolje.
Klasični SEO nas je naučil pisati za ljudi ob upoštevanju iskalnikov; LLMSEO nas uči pisati za ljudi in za AI hkrati.
Vsebina, ki je res koristna, jasna, strukturirana in verodostojna, bo našla pot do občinstva.
Četudi preko posrednika kot je ChatGPT.
Ne zadovoljimo se več le s tem, da prepričamo uporabnika, naj klikne – zdaj moramo prepričati še jezikovni model, naj izbere prav naš odstavek.
Kdor to osvoji, bo v svetu iskanja brez klika užival konkurenčno prednost.
Blaž Pregelj
Ljubitelj ter raziskovalec umetne inteligence, igrifikacije in digitalnega marketinga. O vsem tem in še čem pišem na svojem blogu in podjetju brainylab.